
Using NER for Economic Impact Evaluation
Named Entity Recognition (NER) has the power to extract crucial insights from vast amounts of unstructured economic data, revolutionizing evidence-based policy-making.

Imagine unlocking the power to extract crucial insights from vast amounts of unstructured economic data, revolutionizing evidence-based policy-making. Enter EconBERTa, the groundbreaking language model that's transforming how we analyze and understand the complex world of economics. 🔍💰
In this article, we'll dive deep into the inner workings of EconBERTa, exploring how it tackles the challenges of named entity recognition in the economics domain. Discover how this cutting-edge model, built upon the state-of-the-art mDeBERTa-v3 architecture, achieves unparalleled performance in identifying causal entities and extracting valuable knowledge from economic research papers.
Join me on this exciting journey as I share my experience implementing the EconBERTa paper, from the initial problem statement to the nitty-gritty details of the code. Whether you're an NLP enthusiast, an economics researcher, or simply curious about the latest advancements in AI, this article will provide you with a comprehensive understanding of EconBERTa's potential to reshape the landscape of economic analysis. 🚀📈
Let’s start with learning about the two main topics of this article: named entity recognition and impact evaluation.
What is Named Entity Recognition?
Named entity recognition (NER) is a method to identify and categorize ‘named entities’ in textual data into predefined categories. These ‘named entities’ could be anything from the names of places, locations, or even custom-defined entities for a particular task. NER helps in extracting structured information from unstructured text, which can be used for various downstream tasks.
For example, in the sentence “Akash works at Flipkart in Bengaluru”, NER would identify “Akash” as a person, “Flipkart” as an organization, and “Bengaluru” as a location. This structured information can then be used for further analysis or preprocessing.

What is Impact Evaluation?
In short, impact evaluations (IE) provide information about the impacts produced by programs and policies. By using impact evaluations, we know how effective our programs are and can make good, cost-effective decisions about future programs. Some good sources to understand IE are World Bank - What is Impact Evaluation? and Building Blocks of Impact Evaluation.

Tl;DR
The authors proposed EconBERTa, an LLM based on mDeBERTa-v3, as well as a new dataset ECON-IE for the downstream NER task. EconBERTa enhances NER for causal entities in economic research data with state-of-the-art performance. Additionally, the newly created ECON-IE dataset helps in extracting causal knowledge in economics.
The authors also analyzed the model’s generalization capabilities. Analyzing the generalization abilities paved the way for us to do robustness analysis and we complemented the authors’ efforts with the addition of multilingual support. Given limited resources and time, we couldn’t reproduce the results from the paper, but we did reproduce the trend in the f1-scores of the models.

Introduction
So far named entity recognition (NER) has been implemented in domains like science, medicine, finance, and social media. Researchers have also built datasets to improve and compare the performances of NER models in these domains. These downstream tasks benefit from NER models by using the extracted information from unstructured text for event detection and building knowledge bases.
The Problem
Here are the major three problems that we're going to address:
In medicine, NER models can allow clinicians and medical researchers to determine which medication is an effective treatment for a specific disease. Similarly, knowing which policy intervention produces a certain economic outcome is imperative for evidence-based policy-making. Although much work has been done in biomedical research to identify relevant causal entities, this has not been explored in the economics domain for Impact Evaluation (IE).
Studies show that pretraining a language model on documents from the same domain as the downstream task improves performance in two ways (i) by in-domain pretraining from scratch, or (ii) by further in-domain pretraining from the weights of an existing general-purpose model. While pretrained models are present across many domains, economics is yet to follow suit.
Assessing the performance of a model is often done after fine-tuning but the knowledge gained by such transfer learning approach is opaque. Therefore, it remains unclear which aspects of the model need improvement to increase its robustness during deployment. And to understand the weakness of a state-of-the-art (SOTA) model, we need to understand the notion of generalization. But we lack its precise definition.
So how do we fix these?
The Proposal
Well, there are three proposals:
The authors propose ECON-IE, a NER dataset of 1,000 abstracts from economic research papers annotated for entities describing the causal effects of policy interventions: outcome, population, effect size, intervention, and coreference. This dataset is the first of its kind and lays the foundation of causal knowledge extraction in economics.
The authors contributed EconBERTa, a language model pretrained on 1.5 million scientific papers from economics, demonstrating that it outperforms open-source general-purpose pretrained models on the benchmark dataset ECON-IE.
The authors evaluate the generalization capability of the finetuned NER model by performing a series of diagnostic tests from the Checklist paper.
The authors' source code implementation (using AllenNLP) is available at https://github.com/worldbank/econberta-econie. You can also find information about the related work in great detail in the paper.

Experiments
So far we have seen the problems faced in this domain and the proposed solutions to alleviate them. This gives us a clear direction to head into before we start coding. But before we can jump into coding the solutions, let’s have a quick look at the dataset.
The Dataset
The ECON-IE dataset consists of text from 100 abstracts summarizing impact evaluation (IE) studies from economics research papers, totaling more than 7000 sentences. It is sampled from 10,000 studies curated by 3ie2. Stratified sampling has been performed to maximize the diversity of the annotated sample.
The proposed model involves pretraining and finetuning the models with the ECON-IE dataset and comparing results. The dataset was collected and annotated for the following entities describing the causal effects of policy interventions: outcome, population, effect size, intervention, and coreference.

Implementation
The central claim of the paper is that EconBERTa reaches SOTA performance on downstream NER tasks. There are two versions of EconBERTa (i) EconBERTa-FS pretrained from scratch on economic vocabulary and (ii) EconBERTa-FC loaded from mDeBERTa’s checkpoint and then fine-tuned on ECON-IE dataset for the NER task. The author has also compared the performance of EconBERTa with that of BERT, RoBERTa, and mDeBERTa-v3 on the given dataset.
We did not have enough resources to pretrain the entire model from scratch so we ruled out reproducing results from the EconBERTa-FS version and focused on fine-tuning the EconBERTa-FC checkpoint from huggingface.co using ECON-IE dataset and its results.
Baseline Models
We compare our fine-tuned EconBERTa-FC to mDeBERTa-v3-base as it has the same architecture. We also compared it with BERT-base-uncased and RoBERTa-base on the given dataset in line with the authors’ approach.
NER fine-tuning
The fine-tuned NER model relies on a Conditional Random Field (CRF) layer for classification. All the trainings were conducted using a custom model defined as CRFTagger created by adding a CRF layer at the end, mimicking AllenNLP’s implementation of crf_taggger method. The hyperparameters used were given by the authors in the paper.

What is a CRF layer?
A CRF layer takes into account the dependencies between adjacent labels in a sequence and jointly decodes the most likely sequence of labels. There are multiple reasons why we might want this for an NER task:
Label dependencies: NER involves predicting a label for each token in a sequence, and these labels often have dependencies on each other. For example, an "I-organization" label is more likely to follow a "B-organization" label than an "I-person" label. A CRF layer explicitly models these dependencies between adjacent labels, allowing the model to make more informed predictions.
Joint decoding: Instead of making independent label predictions for each token, a CRF layer performs joint decoding, considering all possible label sequences and finding the most likely one. This global optimization helps ensure the predicted label sequence is coherent and follows the constraints of the NER task, such as not having an "I-" label without a preceding "B-" label.
Improved performance: Studies have shown that adding a CRF layer on top of neural network architectures like BERT or BiLSTM improves NER performance compared to using the neural network alone. The CRF layer helps refine the predictions made by the underlying neural network, leading to higher precision and recall scores.
All right, with that out of the way, let’s have a look at the code!
Code
Make sure you have the following packages installed:
transformers
torch
transformers[torch]
tokenizers
huggingface_hub
pytorch-crf
checklist
protobuf==3.20.3
Import packages and check if you have an Nvidia GPU (if you want to run it on another hardware, assign the device variable to it, and all the best!)
import torch
torch.cuda.empty_cache()
assert torch.cuda.is_available()
device_name = torch.cuda.get_device_name()
n_gpu = torch.cuda.device_count()
print(f"Found device: {device_name}, n_gpu: {n_gpu}")
device = torch.device("cuda")We used a 40GB MIG slice of NVIDIA A100-SXM4-80GB GPU to fine-tune the models.
Now, the first thing we did was to seed everything. We used a custom seed method throughout our code for reproducibility. My professor shared this method in one of the assignments in the class and I have been using it ever since.
import random
import numpy as np
# Ensure reproducibility
def seed_everything(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = Trueseed_everything()Then we set the hyperparameters before doing anything else so that there is one place to modify them and run the notebook again when required.
# Set the hyperparameters according to Table 8
dropout = 0.2
learning_rates = [5e-5, 6e-5, 7e-5] # Perform hyperparameter search
batch_size = 12
gradient_accumulation_steps = 4
weight_decay = 0
max_epochs = 10
lr_decay = "slanted_triangular"
fraction_of_steps = 0.06
adam_epsilon = 1e-8
adam_beta1 = 0.9
adam_beta2 = 0.999Once we are sure that everything that depends on a random generator is seeded, we load the dataset into a dataframe. Then take this dataframe and convert it to the required dataset format. This dataset is a tuple of a list of (input_ids, attention_masks, labels) tuples and the sentences themselves ([(input_id, attention_mask, label)], sentence). We created custom methods to read the data into dataframes, tokenize and format them, and return them into the desirable format.
train_df = read_conll('../data/econ_ie/train.conll')
val_df = read_conll('../data/econ_ie/dev.conll')
test_df = read_conll('../data/econ_ie/test.conll')
train_set, train_sentences = get_dataset(train_df, tokenizer, label_dict)
val_set, val_sentences = get_dataset(val_df, tokenizer, label_dict)
test_set, test_sentences = get_dataset(test_df, tokenizer, label_dict)We also defined an enum class to reuse the model names. The class also contains multilingual models which we used to extend the paper.
# Define an enum for model names
class ModelName(Enum):
BERT = 'google-bert/bert-base-uncased'
BERT_multilingual = 'google-bert/bert-base-multilingual-uncased'
ROBERTA = 'FacebookAI/roberta-base'
XLM_ROBERTA = 'FacebookAI/xlm-roberta-base'
MDEBERTA = 'microsoft/mdeberta-v3-base'
ECONBERTA_FC = 'worldbank/econberta'
ECONBERTA_FS = 'worldbank/econberta-fs'Then we defined the label_dict to map labels to numbers and reverse_label_dict for vice-versa.
label_dict = {
'O': 0,
'B-intervention': 1,
'I-intervention': 2,
'B-outcome': 3,
'I-outcome': 4,
'B-population': 5,
'I-population': 6,
'B-effect_size': 7,
'I-effect_size': 8,
'B-coreference': 9,
'I-coreference': 10
}
reverse_label_dict = {v: k for k, v in label_dict.items()}We loaded the pretrained model making sure that it was capable of performing the NER task. To do this, we need to add a CRF layer at the end as the classification layer to this model. We created a custom wrapper to add this layer to the existing model.
from torchcrf import CRF
from transformers import AutoModel
class CRFTagger(torch.nn.Module):
def __init__(self, model_name, num_labels):
super().__init__()
self.bert = AutoModel.from_pretrained(model_name)
self.dropout = torch.nn.Dropout(dropout)
self.classifier = torch.nn.Linear(self.bert.config.hidden_size, num_labels)
self.crf = CRF(num_labels, batch_first=True)
def forward(self, input_ids, attention_mask, labels=None):
outputs = self.bert(input_ids, attention_mask=attention_mask)
sequence_output = outputs[0]
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
# Mask should be of type 'bool' in newer PyTorch versions
mask = attention_mask.type(torch.bool) if hasattr(torch, 'bool') else attention_mask.byte()
if labels is not None:
loss = -self.crf(logits, labels, mask=mask, reduction='mean')
return {'loss': loss, 'logits': logits, 'decoded': self.crf.decode(logits, mask=mask)}
else:
decoded_labels = self.crf.decode(logits, mask=mask)
return {'decoded': decoded_labels, 'logits': logits}seed_everything()
# Load the pre-trained model
model = CRFTagger(model_name, len(label_dict))
model.dropout = torch.nn.Dropout(dropout)
model.to(device)Then we start fine-tuning the model. We used the hyperparameters defined by the authors for this and created some more custom methods to support the evaluation of the model and to analyze the generalization.
The training loop goes through the defined learning rates and for each rate creates an optimizer and a scheduler. It then runs the training for the given number of epochs. We print the total loss at the end of each epoch to track the performance and get the performance on the dev set as well. We used a lot of custom methods to analyze the generalization of this model. These methods are all in our repository here.
If you want to run through the entire code, we have a Colab Notebook that you can play with here. This notebook is comprehensive and has the code of our entire experiment including robustness analysis with tests on LLM following the Checklist paper. We explored multilinguality of the model in another notebook.
Approach and Results
The dataset is divided into 3 parts: train.conll, test.conll, and dev.conll. The authors also provide a full.conll file that we didn’t come to use. The data in these files have two columns. The first column is tokens and the second column has its corresponding label.
We tried two methods of loading the data and running the training loop:
Initially, we used a token-based approach, passing each token/word to the training loop and processing them one at a time.
Then we tried a sentence-based approach, loading the entire sentence and processing it in batches.
[❗️Spoiler Alert❗️] The sentence-based approach turned out to be 10x faster than the token-based approach. It took us ~50 mins per epoch using the token-based approach whereas ~5 mins per epoch with the sentence-based approach. Not just that, the dev f1-score of the former was also considerably worse than the latter. Hence, we stuck to the sentence-based approach.

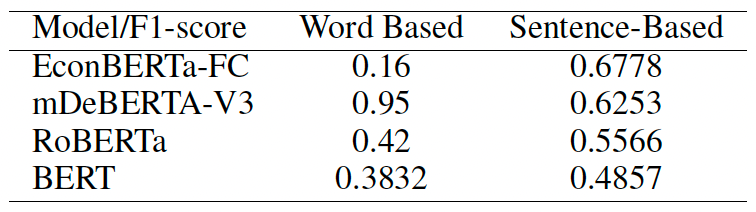
The code that we have provided corresponds to the sentence-based method only as it is the one that was relevant to us. We developed code from scratch using PyTorch to integrate with Huggingface Transformers, enabling us to train and test models against the provided dataset, aiming for results matching the original study. This phase required advanced programming skills and deep model understanding.
This process involved rigorous debugging, optimization, and experimentation to achieve competitive performance metrics comparable to the state-of-the-art results reported in the literature.
Entity-level evaluation
Previous work has argued that comparing F1-scores on dev set cannot highlight strengths and weaknesses of the model under test. F1-score is computed at a token level in NER. Instead of considering each token on its own, one solution might be to measure whether the entire span of an entity is accurately predicted.

In our efforts to replicate the results reported by the authors in their model comparisons, we encountered significant discrepancies earlier between the expected and observed performances of the models. However, we were able to fix the approach as explained earlier (token-based vs sentence-based) and get better results.
We performed error analysis and plotted the graph to see the proportion of Exact Match, and other error types proposed in the paper and compared it to the authors’ results.
We were able to get most of the tokens partially correct within the boundaries while the authors got most of them exactly within the boundary for the shortest entity length.
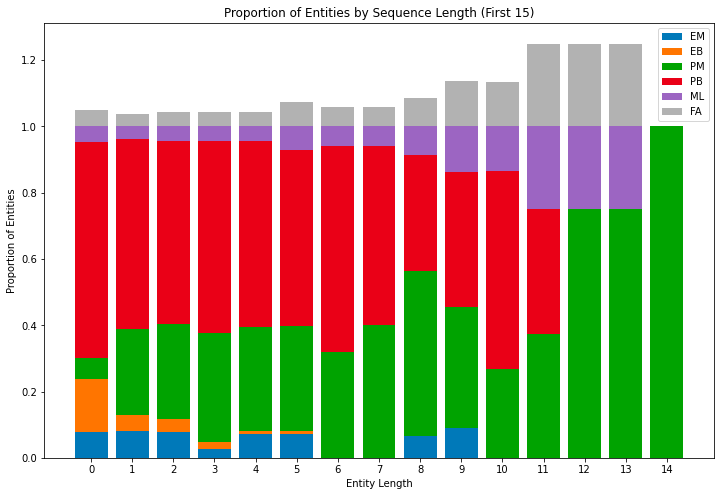

The authors also discussed the possibility of lexical memorization but we did not have enough time to dive into it. However, we performed a robustness check and tested multilingual abilities of the model which was not done by the authors. Those are discussed in great detail in the project report which you can find in our repository here.
Thank you for reading this far! If you have any suggestions for me to improve my writing please do not hesitate to reach out to me through LinkedIn, 𝕏, or email me at ashutoshpathak@thenumbercrunch.com.
Regarding the article, a trully insightful look at EconBERTa. Causal inference is indeed complex.